Cum de a crea propria rețea neurală de la zero în Python. Studiem rețelele neuronale în patru pași cum să scriem inteligență artificială pe Python
Dar, într-adevăr, dorința de a crea o inteligență artificială perfectă, indiferent dacă este un model de joc sau un program mobil, a venit pe calea programatorului mulți dintre noi. Problema este că în spatele tone de material educațional și realitatea aspră a clienților, aceasta este dorințele înlocuite de o dorință simplă de auto-dezvoltare. Pentru cei care nu au început niciodată executarea viselor copiilor, atunci un scurt ghid pentru a crea o minte artificială reală.
Etapa 1. Dezamăgirea
Când vorbim despre crearea unui bot simplu simplu, ochii sunt umpluți cu strălucire, iar sute de idei au strălucit în cap că ar trebui să poată face. Cu toate acestea, atunci când vine vorba de implementare, se pare că cheia pentru rezolvarea modelului real de comportament este ... matematică. Pentru a fi un pic mai precis, aici este lista partițiilor sale care trebuie deplasate cel puțin în formatul învățământului universitar:
-
Teoria graficelor;
Teoria probabilităților și statisticilor matematice.
Algebră liniară;
Aceasta este capul științific, la care va fi construit programele dvs. suplimentare. Fără cunoașterea și înțelegerea acestei teorii, toate ideile vor sparge rapid interacțiunea cu o persoană, deoarece mintea artificială nu este de fapt decât un set de formule.
Etapa 2. Adoptarea
Când somnul este un pic împușcat de literatura de studenți, puteți începe să învățați limbi. Nu merită să vă grăbiți la Lisp sau pe alții încă, mai întâi trebuie să învățați cum să lucrați cu variabile și state fără echivoc. În ceea ce privește studiul rapid și dezvoltarea ulterioară este perfectă, dar, în general, puteți lua baza oricărei limbi cu bibliotecile relevante.
Etapa 3. Dezvoltare
Acum mergeți direct la teoria AI. Ele pot fi împărțite în 3 categorii:
AI slabă sunt boturile pe care le vedem în jocuri pe calculator sau a unor ajutoare sănătoase sănătoase, cum ar fi Siri. Ei sau îndeplinesc sarcini foarte specializate sau sunt un complex minor de acelea și orice imprevizibilitate a interacțiunii le pune într-un capăt mort.
AI puternică este mașinile a căror inteligență este comparabilă cu creierul uman. Până în prezent, nu există reprezentanți reali ai acestei clase, dar computerele, cum ar fi Watson, sunt foarte aproape de atingerea acestui obiectiv.
Perfect AI este viitorul, un creier de mașină care va depăși capacitățile noastre. Este vorba despre pericolul unor astfel de evoluții pe care Stephen Hoking, Elon Mask și Fransprishis "Terminator" avertizează.
Firește, ar trebui să începeți cu cele mai simple roboți. Pentru a face acest lucru, amintiți-vă de jocul vechi "Tick-uri încrucișate" atunci când utilizați câmpul 3x3 și încercați să găsiți algoritmii de acțiuni de bază: probabilitatea de victorie în cazul unor acte fără erori, cele mai de succes locuri de pe Câmpul pentru locația figurii, necesitatea de a reduce jocul la o remiză și așa mai departe.
Așa cum ați înțeles chiar și din nume, este un API care nu va permite nu mai mult timp pentru a crea o asemănare a AI gravă.

Etapa 5. Lucrul
Acum, când vă imaginați deja în mod clar cum să creați și cum să îl utilizați, este timpul să vă retrageți cunoștințele la un nou nivel. În primul rând, acest lucru va necesita studiul disciplinei numit "antrenament de mașină". În al doilea rând, trebuie să învățați cum să lucrați cu bibliotecile relevante ale limbajului de programare selectat. Pentru Python considerat de noi este Scikit-Aflați, NLTK, SCIPY, PYBRAIN și NUPP. În al treilea rând, în dezvoltarea oriunde nu poate face de la
De data aceasta am decis să explorez rețelele neuronale. Abilități de bază în această chestiune am reușit să trec peste vară și toamna anului 2015. În conformitate cu abilitățile de bază, vreau să spun că pot crea o rețea neurală simplă de la zero. Exemple pot fi găsite în depozitele mele de pe GitHub. În acest articol, voi da câteva clarificări și voi împărtăși resursele care vă pot fi utile pentru a explora.
Pasul 1. Neuroni și metoda de distribuție directă
Deci, care este "rețeaua neurală"? Să așteptăm cu asta și să înțelegem mai întâi un neuron.
Neuronul este similar cu funcția: este nevoie de câteva valori pentru a intra și întoarce unul.
Cercul de mai jos indică neuron artificial. Acesta primește 5 și returnează 1. Enter - aceasta este suma a trei SINAP-uri conectate cu neuron (trei săgeți în stânga).
În partea stângă a imaginii vedem 2 valori de intrare (verde) și offset (evidențiate cu maro).
Datele de intrare pot fi reprezentări numerice de două proprietăți diferite. De exemplu, atunci când creați un filtru de spam, ar putea însemna prezența a mai mult de un cuvânt scrisă prin majuscule și prezența cuvântului "Viagra".
Valorile de intrare sunt înmulțite cu așa-numitele "greutăți", 7 și 3 (evidențiate în albastru).
Acum pliam valorile obținute cu deplasarea și primim un număr în cazul nostru 5 (evidențiat în roșu). Aceasta este introducerea neuronului nostru artificial.

Apoi, neuronul produce un fel de calcul și emite valoarea de ieșire. Avem 1, pentru că Valoarea rotunjită a sigmoidului la punctul 5 este 1 (în detaliu despre această funcție, să vorbim mai târziu).
Dacă ar fi fost un filtru de spam, ieșirea de 1 ar însemna că textul a fost etichetat cu neuron ca spam.

Ilustrație a unei rețele neuronale cu Wikipedia.
Dacă combinați aceste neuroni, atunci obțineți o rețea neuronală distribuită direct - procesul provine de la intrare la ieșire, prin neuroni conectați prin sinapse, ca în imaginea din stânga.
Pasul 2. Sigmoid.
După ce ați analizat lecțiile din Laboratoarele Welch, o idee bună ar fi familiarizată cu cea de-a patra săptămână de curs de învățare a mașinilor de la Cursuri dedicate rețelelor neuronale - va contribui la înțelegerea principiilor muncii lor. Cursul este foarte aprofundat în matematică și se bazează pe octavă și prefer Python. Din acest motiv, am pierdut exercițiile și am învățat toate cunoștințele necesare din videoclip.

Sigmoid Pur și simplu afișează valoarea dvs. (axa orizontală) pe un segment de la 0 la 1.
Prima prioritate pentru mine a fost studiul sigmoidului, așa cum a apărut în multe aspecte ale rețelelor neuronale. Ceva despre ea am știut deja din a treia săptămână a cursului de mai sus, așa că am revizuit videoclipul de acolo.
Dar pe unele videoclipuri nu vor pleca. Pentru o înțelegere completă, am decis să plâng singur. Prin urmare, am început să scriu implementarea algoritmului de regresie logistică (care utilizează sigmoid).
A luat toată ziua și cu greu rezultatul a fost satisfăcător. Dar nu contează, pentru că mi-am dat seama cum funcționează totul. Codul poate fi văzut.
Nu este nevoie să o faceți singur, deoarece cunoașterea specială este necesară aici - principalul lucru este că înțelegeți cum este aranjat Sigmoid.
Pasul 3. Mod de distribuire a erorilor inverse
Înțelegeți principiul funcționării rețelei neuronale de la intrare la ieșire nu este atât de dificil. Este mult mai greu să înțelegeți cum este învățată rețeaua neurală pe seturile de date. Principiul folosit de mine este numit
James Loy, Georgia Technology University of Technology. Ghid pentru începători, după care puteți crea propria rețea neurală pe Python.
Motivația:concentrându-se pe experiența personală în învățarea formării profunde, am decis să creez o rețea neurală de la zero fără o bibliotecă complexă de formare, cum ar fi, de exemplu,. Cred că pentru novice de date de știință, este important să înțelegem structura internă a rețelei neuronale.
Acest articol conține ceea ce am învățat și sper că va fi util pentru dvs.! Alte articole utile pe tema:
Ce este o rețea neuronală?
Majoritatea articolelor din rețelele neuronale sunt efectuate cu paralelele creierului. Este mai ușor să descriu rețelele neuronale ca o funcție matematică care afișează intrarea specificată la rezultatul dorit, care nu este livrat în detalii.
Rețelele neuronale constau din următoarele componente:
- stratul de admisie, x
- număr arbitrar. Straturile ascunse
- stratul de ieșire, ŷ
- a stabilit cântărește și deplasările Între fiecare strat W. și b.
- alegere funcțiile de activare Pentru fiecare strat ascuns σ ; În această lucrare vom folosi caracteristica de activare Sigmoid.
Diagrama de mai jos prezintă arhitectura unei rețele neuronale cu două straturi (rețineți că nivelul de intrare este de obicei exclus la numărarea numărului de straturi din rețeaua neuronală).
Crearea unei clase de rețea neuronală pe Python arată simplu:
Formarea rețelei neuronale
Ieșire ŷ rețea neuronală simplă cu două straturi:
În ecuația de mai sus, greutatea w și offset b sunt singurele variabile care afectează ieșirea ŷ.
Bineînțeles, valorile corecte pentru greutăți și deplasări determină acuratețea predicțiilor. Procesul de scale de reglare fină și offsets din datele de intrare este cunoscut sub numele de formarea rețelei neuronale.
Fiecare iterație a procesului de învățare constă în următorii pași
- calcularea ieșirii prezise ŷ numită distribuție directă
- actualizarea greutăților și deplasărilor numite inverse
Graficul serial de mai jos ilustrează procesul:

Distribuție directă
După cum am văzut pe graficul de mai sus, distribuția directă este pur și simplu o computere ușoară și pentru rețeaua neuronală de bază cu 2 straturi, retragerea rețelei neuronale este dată de formula:
Să adăugăm o funcție de distribuție directă la codul nostru pe Python-E pentru a face acest lucru. Rețineți că pentru simplitate, am sugerat că compensarea este egală cu 0.
Cu toate acestea, aveți nevoie de o modalitate de a evalua "calitatea" prognozelor noastre, adică cât de departe sunt previziunile noastre). Funcția de pierdere Doar ne permite să o facem.
Funcția de pierdere
Există multe funcții de pierdere disponibile, iar natura problemei noastre ar trebui să ne dicteze o alegere a unei funcții de pierdere. În această lucrare vom folosi suma pătratelor de erori Ca o funcție de pierdere.

Cantitatea de pătrate de eroare este diferența medie dintre fiecare valoare previzibilă și cea reală.
Scopul învățării este de a găsi un set de scale și deplasări care minimizează funcția de pierdere.
Distribuția inversă
Acum că am măsurat eroarea de prognoză (pierdere), trebuie să găsim o cale Diseminarea erorii înapoi și actualizați greutățile și offseturile noastre.
Pentru a afla cantitatea potrivită pentru a ajusta greutățile și deplasările, trebuie să cunoaștem funcția derivată a pierderii în ceea ce privește greutățile și offseturile.
Rechemați din analiza funcția derivată este un unghi tangent de înclinare a funcției.

Dacă avem un derivat, atunci putem actualiza pur și simplu greutățile și offseturile, creșterea / reducerea acestora (vezi graficul de mai sus). Se numeste gradient descendent..
Cu toate acestea, nu putem calcula direct derivatul funcției de pierdere față de greutăți și deplasări, deoarece ecuația funcției de pierdere nu conține scale și deplasări. Prin urmare, avem nevoie de o regulă a lanțului pentru a ajuta la calculator.

Fuch! A fost greoaie, dar a permis să obțină ceea ce avem nevoie - un derivat (înclinare) al pierderii funcțiilor în raport cu greutățile. Acum putem ajusta în mod corespunzător greutățile.
Adăugați caracteristica de backpropagare a codului nostru pe Python-E:
Verificarea activității neuroseticelor
Acum că avem codul nostru complet pe Python-E pentru a efectua o distribuție directă și inversă, să ne uităm la rețeaua noastră neuronală de exemplu și să vedem cum funcționează.
 Setul perfect de scale
Setul perfect de scale Rețeaua noastră neuronală ar trebui să exploreze setul perfect de scale pentru prezentarea acestei funcții.
Să pregătim rețeaua neurală timp de 1500 de iterații și să vedem ce se întâmplă. Având în vedere programul pierderilor privind iterațiile de mai jos, putem vedea clar că pierderea monotonică scade la minimum. Acest lucru este în concordanță cu algoritmul de coborâre a gradientului, pe care l-am spus mai devreme.
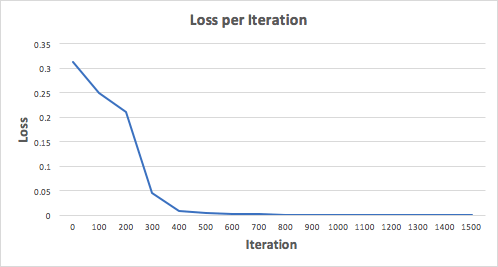
Să ne uităm la predicția finală (ieșire) din rețeaua neuronală după 1500 de iterații.

Am reusit!Algoritmul nostru de diseminare directă și de returnare a arătat funcționarea cu succes a rețelei neuronale, iar previziunile converg asupra valorilor reale.
Rețineți că există o mică diferență între predicții și valori reale. Acest lucru este de dorit deoarece împiedică mai bine rețelei neuronale să generalizeze date invizibile.
Reflecții finale
Am învățat foarte mult în procesul de scriere de la zero a rețelei mele neurale. Deși bibliotecile de învățare profundă, cum ar fi Tensorflow și Keras, permit crearea de rețele profunde fără o înțelegere completă a activității interioare a rețelei neuronale, consider că novice Data de știință-am este utilă pentru a obține înțelegerea mai profundă.
Mi-am investit o mulțime de timp personal în această lucrare și sper că va fi util pentru tine!
Acum experimentăm un adevărat boom de rețele neuronale. Acestea sunt utilizate pentru recunoaștere, localizare și prelucrare a imaginilor. Rețelele neuronale sunt deja în măsură să facă multe care nu sunt disponibile unei persoane. Este necesar să încorporați în acest caz! Luați în considerare rețeaua de neutroni care va recunoaște numerele de pe imaginea de intrare. Totul este foarte simplu: doar o singură funcție și o funcție de activare. Nu ne va permite să recunoaștem absolut toate imaginile de testare, dar vom face față majorității covârșitoare. Ca date, vom folosi recunoașterea mondială în lumea selecției de date MNIST.
Pentru a lucra cu el în Python, există o bibliotecă Python-Mnist. A instala:
PIP instalați Python-Mnist
Acum putem încărca date
De la importul Mnist Mnist MnDATA \u003d Mnist ("/ PATH_TO_MNIST_DATA_FOLDER /") tr_IMages, Tr_labels \u003d MNDATA.LABLY_TRAINING () test_images, test_labels \u003d MNDATA.LABLY_TESTING ()
Arhivele cu datele trebuie să fie descărcate independent, iar programul specifică calea către catalog cu ele. Acum variabilele TR_IMages și test_images conțin imagini pentru crearea de rețele și testarea corespunzătoare. Iar variabilele TR_Labels și test_labels sunt etichete cu clasificarea corectă (adică cifre din imagini). Toate imaginile sunt dimensiunea 28x28. Specificați variabila cu dimensiunea.
IMG_SHAPE \u003d (28, 28)
Convertiți toate datele în matricele NOPY și le normalizăm (dau dimensiunea de la -1 la 1). Aceasta va spori acuratețea calculelor.
Importați NPPY ca np pentru i în raza de acțiune (0, len (test_images)): test_images [i] \u003d np.array (test_images [i]) / 255 pentru i în intervalul (0, len (tr_images)): tr_images [i] \u003d Np.array (tr_images [i]) / 255
Observ că, deși imaginile sunt luate pentru a reprezenta sub forma unei matrice bidimensionale, vom folosi unidimensional, este mai simplu pentru calcul. Acum trebuie să înțelegeți "Care este rețeaua neurală"! Și aceasta este doar o ecuație cu un număr mare de coeficienți. Avem o matrice de 28 * 28 \u003d 784 elemente la intrare și la o altă greutate 784 pentru a determina fiecare cifră. În timpul funcționării rețelei neuronale, înmulțiți valorile intrărilor de greutate. Plasat datele și adăugați offset. Rezultatul este aplicat funcției de activare. În cazul nostru, va fi relu. Această caracteristică este zero pentru toate argumentele negative și argumentele pentru toate pozitive.

Există încă multe caracteristici de activare! Dar aceasta este cea mai ușoară rețea neuronală! Definim această caracteristică cu Numpy
Def relu (x): retur np.maximum (x, 0)
Acum, pentru a calcula imaginea din imaginea, trebuie să calculați rezultatul pentru 10 seturi de coeficienți.
Def nn_calculatul (IMG): resp \u003d lista (intervalul (0, 10)) pentru i în raza de acțiune (0,10): r \u003d w [: i] * img r \u003d relu (np.sum (r) + b [i] ) Resp [i] \u003d r retur np.argmax (resp)
Pentru fiecare set, vom obține un rezultat de ieșire. Ieșirea cu cel mai mare rezultat este cel mai probabil că există numărul nostru.

În acest caz, 7. Asta-i tot! Dar nu ... pentru că trebuie să luați acești coeficienți foarte undeva. Trebuie să antrenezi rețeaua noastră neuronală. Pentru a face acest lucru, utilizați metoda de eroare inversă. Esența sa este de a calcula ieșirile de rețea, comparați-le cu cele corecte și apoi îndepărtați-vă de rapoartele numărul pe care rezultatul este corect. Trebuie să fie amintit că, pentru a calcula aceste valori, este necesară un derivat al funcției de activare. În cazul nostru, este zero pentru toate numerele negative și 1 pentru toți pozitivi. Definim coeficienții aleatoriu.
W \u003d (2 * np.random.rand (10, 784) - 1) / 10b \u003d (2 * np.random.rand (10) - 1) / 10 pentru n în interval (LEN (Tr_Images)): img \u003d Tr_IMages [n] CLS \u003d Tr_labels [n] #Forward Propagare resp \u003d np.zeros (10, dtype \u003d np.float32) pentru i în raza de acțiune (0,10): r \u003d w [i] * img r \u003d relu (np. Sumă (r) + b [i]) resp [i] \u003d r respi-cls \u003d np.argmax (resp) resp \u003d np.zeros (10, dtype \u003d np.float32) resp \u003d 1.0 # Backing Propagare TRUE_RESP \u003d NP. Zeros ( 10, dtype \u003d np.float32) TRUE_RESP \u003d 1.0 Eroare \u003d RES - TRUE_RESP Delta \u003d eroare * ((resputie\u003e \u003d 0) * np.ones (10)) pentru i în interval (0,10): w [i] - \u003d np .dot (img, delta [i]) b [i] - \u003d Delta [i]
În procesul de învățare, coeficienții vor fi puțin similari cu numerele:
Verificați acuratețea muncii:
Def nn_calculatul (IMG): RESP \u003d Lista (interval (0, 10)) pentru i în interval (0,10): r \u003d w [i] * img r \u003d np.maximum (np.sum (r) + b [i] , 0) #Lelu resp [i] \u003d r retur np.argmax (resp) total \u003d len (test_images) valid \u003d 0 invalid \u003d pentru i în raza de acțiune (0, total): img \u003d test_images [i] prezicate \u003d nn_calculate (img ) TRUE \u003d test_labels [i] dacă este prezis \u003d\u003d Adevărat: valid \u003d valid + 1 altceva: Invalid.append (("imagine": img ", a prezis": "Adevărat": true)) imprimare ("Precizie () "Format (valabil / total))
Am 88%. Nu atât de cool, dar foarte interesant!