Comment créer votre propre réseau neuronal à partir de zéro dans Python. Nous étudions les réseaux de neurones en quatre marches comment écrire une intelligence artificielle sur Python
Mais vraiment, c'est le désir de créer une intelligence artificielle parfaite, qu'il s'agisse d'un modèle de jeu ou d'un programme mobile, est devenu à la voie du programmeur beaucoup d'entre nous. Le problème est que derrière des tonnes de matériel pédagogique et la dure réalité des clients, c'est que les souhaits ont été remplacés par un simple désir d'auto-développement. Pour ceux qui n'ont jamais commencé l'exécution des rêves des enfants, un petit guide pour créer un véritable esprit artificiel.
Étape 1. Déception
Lorsque nous parlons de créer au moins de simples robots, les yeux sont remplis de paillettes et des centaines d'idées ont flashé dans la tête qu'il devrait pouvoir faire. Cependant, lorsqu'il s'agit de la mise en œuvre, il s'avère que la clé de la résolution du modèle de comportement réel est ... Mathématiques. Pour être un peu plus spécifiquement, voici la liste de ses partitions qui doivent être déplacées au moins dans le format de l'enseignement universitaire:
-
Théorie des graphiques;
Théorie de la probabilité et des statistiques mathématiques.
Algèbre linéaire;
C'est la tête de pont scientifique à laquelle votre nouvelle programmation sera construite. Sans la connaissance et la compréhension de cette théorie, toutes les idées se briseront rapidement sur l'interaction avec une personne, car l'esprit artificiel n'est en réalité pas plus qu'un ensemble de formules.
Étape 2. Adoption
Lorsque le sommeil est un peu abattu par la littérature des élèves, vous pouvez commencer à apprendre des langues. Il ne vaut pas la peine de se précipiter à Lisp ou à d'autres personnes, d'abord, vous devez d'abord apprendre à travailler avec des variables et des États non ambiguës. En ce qui concerne l'étude rapide, et un développement ultérieur est parfait, mais en général, vous pouvez prendre la base de toute langue avec les bibliothèques concernées.
Étape 3. Développement
Maintenant, allez directement à la théorie de l'IA. Ils peuvent être divisés en 3 catégories:
Les AI faibles sont les bots que nous voyons dans des jeux informatiques ou des assistants sains ordinaires, comme Siri. Ils effectuent des tâches hautement spécialisées ou sont un complexe mineur de ceux-ci et toute imprévisibilité de l'interaction les met dans une impasse.
L'AI fort est des machines dont l'intelligence est comparable au cerveau humain. À ce jour, il n'y a pas de véritables représentants de cette classe, mais des ordinateurs, comme Watson, sont très proches de la réalisation de cet objectif.
L'AI parfaite est l'avenir, un cerveau de machine qui dépassera nos capacités. Il s'agit du danger de ces développements que Stephen Hokking, un masque Elon et Franmshis "Terminator" avertissent.
Naturellement, vous devriez commencer par les robots les plus simples. Pour ce faire, souvenez-vous de l'ancien jeu «Cross-tick-tiques» lorsque vous utilisez le champ 3x3 et essayez de déterminer les algorithmes d'actions de base: la probabilité de victoire en cas d'actes sans erreur, les endroits les plus réussis sur le Champ pour l'emplacement de la figure, la nécessité de réduire le jeu à un tirage au sort et ainsi de suite.
Comme vous l'avez compris, même des noms, c'est une API qui ne permettra plus le temps de créer une similitude de l'AI sérieux.

Étape 5. Travaux
Maintenant, lorsque vous imaginez déjà clairement comment créer et comment l'utiliser, il est temps de retirer vos connaissances à un nouveau niveau. Premièrement, cela nécessitera l'étude de la discipline appelée «formation de la machine». Deuxièmement, vous devez apprendre à travailler avec les bibliothèques pertinentes du langage de programmation sélectionné. Pour le python considéré par nous est Scikit-apprendre, NLTK, Scipey, Pybrain et Nump. Troisièmement, dans le développement de n'importe où ne peut pas faire de
Cette fois, j'ai décidé d'explorer les réseaux de neurones. Les compétences de base dans cette affaire, j'ai pu passer au-dessus de l'été et de l'automne 2015. Sous les compétences de base, je veux dire que je peux créer un réseau de neurones simple à partir de zéro. Des exemples peuvent être trouvés dans mes référentiels sur GitHub. Dans cet article, je vais donner quelques éclaircissements et partagerai les ressources qui peuvent vous être utiles à explorer.
Étape 1. Neurones et méthode de distribution directe
Alors, quel est le "réseau neuronal"? Attendons-y et d'abord avec un neurone.
Le neuron est similaire à la fonction: il faut quelques valeurs pour entrer et le renvoyer une.
Le cercle ci-dessous indique un neurone artificiel. Il reçoit 5 et renvoie 1. Entrée - c'est la somme de trois Sinaps liés au neuron (trois flèches à gauche).
Dans le côté gauche de l'image, nous voyons 2 valeurs d'entrée (vert) et décalage (surlignées avec Brown).
Les données d'entrée peuvent être des représentations numériques de deux propriétés différentes. Par exemple, lors de la création d'un filtre anti-spam, ils pourraient signifier la présence de plusieurs mots écrits par des lettres majuscules et la présence du mot "viagra".
Les valeurs d'entrée sont multipliées par leurs "poids", 7 et 3 (surlignés en bleu).
Maintenant, nous plions les valeurs obtenues avec le déplacement et obtenez un numéro dans notre cas 5 (en surbrillance en rouge). C'est l'introduction de notre neurone artificiel.

Ensuite, le neurone produit une sorte de calcul et émet la valeur de sortie. Nous avons 1, parce que La valeur arrondie du sigmoïde au point 5 est de 1 (plus en détail sur cette fonction, parlons plus tard).
S'il s'agissait d'un filtre anti-spam, la sortie 1 signifierait que le texte était étiqueté avec Neuron comme spam.

Illustration d'un réseau neuronal avec Wikipedia.
Si vous combinez ces neurones, obtenez un réseau neural directement distribué - le processus provient de l'entrée à la sortie, via des neurones connectés par des synapses, comme dans l'image à gauche.
Étape 2. Sigmoïde
Après avoir examiné les leçons de Welch Labs, une bonne idée serait familiarisée avec la quatrième semaine de cours d'apprentissage de la machine de Coursera dédiée aux réseaux de neurones - cela aidera à comprendre les principes de leur travail. Le cours est très approfondi en mathématiques et est basé sur l'octave et je préfère python. Pour cette raison, j'ai raté les exercices et j'ai appris toutes les connaissances nécessaires de la vidéo.

Sigmoid affiche simplement votre valeur (axe horizontal) sur un segment de 0 à 1.
La première priorité pour moi était l'étude de Sigmoïde, comme il est apparu dans de nombreux aspects des réseaux de neurones. Quelque chose à propos de elle, j'ai déjà su la troisième semaine du cours ci-dessus, j'ai donc révisé la vidéo de là.
Mais sur certaines vidéos ne partiront pas. Pour une compréhension complète, j'ai décidé de pleurer seul. Par conséquent, j'ai commencé à écrire la mise en œuvre de l'algorithme de régression logistique (qui utilise Sigmoid).
Il a fallu toute la journée et le résultat n'a guère été satisfaisant. Mais cela n'a pas d'importance, parce que j'ai compris comment tout fonctionne. Le code peut être vu.
Vous n'avez pas besoin de le faire vous-même, car une connaissance spéciale est requise ici - l'essentiel est que vous comprenez comment le sigmoïde est arrangé.
Étape 3. Méthode de distribution d'erreur inverse
Comprendre le principe de fonctionnement du réseau neuronal de l'entrée à la sortie n'est pas si difficile. Il est beaucoup plus difficile de comprendre comment le réseau neuronal est appris sur les ensembles de données. Le principe utilisé par moi est appelé
James Loy, l'Université de technologie de la technologie de Géorgie. Guide pour les débutants, après quoi vous pouvez créer votre propre réseau de neurones sur Python.
Motivation:en se concentrant sur une expérience personnelle dans l'apprentissage d'une formation profonde, j'ai décidé de créer un réseau de neurones à partir de zéro sans une bibliothèque de formation complexe, telle que, par exemple. Je crois que pour le scientifique des données novices, il est important de comprendre la structure interne du réseau neuronal.
Cet article contient ce que j'ai appris et j'espère que cela vous sera utile! Autres articles utiles sur le sujet:
Qu'est-ce qu'un réseau de neurones?
La plupart des articles sur les réseaux de neurones sont effectués avec les parallèles cérébraux. Il est plus facile pour moi de décrire les réseaux de neurones comme une fonction mathématique qui affiche l'entrée spécifiée au résultat souhaité, non livré dans des détails.
Les réseaux de neurones comprennent les composants suivants:
- couche d'entrée, x
- nombre arbitraire Couches cachées
- couche de sortie,
- ensemble peser et déplacements Entre chaque couche W. et b.
- choix fonctions d'activation Pour chaque couche cachée σ ; Dans ce travail, nous utiliserons la fonctionnalité d'activation sigmoïde.
Le diagramme ci-dessous montre l'architecture d'un réseau neuronal à deux couches (note que le niveau d'entrée est généralement exclu lors du comptage du nombre de couches du réseau neuronal).
Créer une classe de réseau de neurones sur Python semble simple:
Entraînement réseau neuronal
Production ŷ réseau de neurones simple à deux couches:
Dans l'équation ci-dessus, le poids W et le décalage B sont les seules variables qui affectent la sortie ŷ.
Naturellement, les valeurs correctes pour les poids et les déplacements déterminent la précision des prévisions. Le processus de réglage des écailles et des décalages des données d'entrée est appelé formation réseau de neurones.
Chaque itération du processus d'apprentissage consiste en les étapes suivantes
- calcul de la sortie prévue ŷ appelé distribution directe
- mise à jour des poids et déplacements appelés inverse
Le graphique de série ci-dessous illustre le processus:

Distribution directe
Comme nous l'avons vu sur le tableau ci-dessus, la distribution directe est simplement un calcul facile et pour le réseau neuronal de base à 2 couches, le retrait du réseau de neurones est donné par la formule:
Ajoutons une fonction de distribution directe à notre code sur Python-e pour le faire. Notez que pour la simplicité, nous avons suggéré que le décalage est égal à 0.
Cependant, vous avez besoin d'un moyen d'évaluer la "qualité" de nos prévisions, c'est-à-dire à quelle distance nos prévisions sont). Fonction de perte Nous permet de le faire.
Fonction de perte
Il existe de nombreuses fonctions de perte disponibles et la nature de notre problème devrait nous dicter le choix de la fonction de perte. Dans ce travail, nous utiliserons la somme des carrés d'erreurs En fonction de la perte.

La quantité de carrés d'erreur est la différence moyenne entre chaque valeur prédite et réelle.
L'apprentissage est de trouver un ensemble d'échelles et de déplacements minimisant la fonction de perte.
Distribution inverse
Maintenant que nous avons mesuré notre erreur de prévision (perte), nous devons trouver un moyen Diffusion de l'erreur et mettre à jour nos poids et nos compensations.
Pour connaître le bon montant pour ajuster les poids et les déplacements, nous devons connaître la fonction dérivée de la perte en ce qui concerne les poids et les compensations.
Rappeler de l'analyse qui la fonction dérivée est un angle d'inclinaison tangente de la fonction.

Si nous avons un dérivé, nous pouvons simplement mettre à jour les poids et les compensations, augmenter / les réduire (voir tableau ci-dessus). On l'appelle descente graduelle.
Cependant, nous ne pouvons pas calculer directement la dérivée de la fonction de perte relative aux poids et aux déplacements, car l'équation de la fonction de perte ne contient pas de balances et de déplacements. Par conséquent, nous avons besoin d'une règle de chaîne pour aider au calcul.

Fauch! C'était lourd, mais autorisé à obtenir ce dont nous avons besoin - une dérivée (inclinaison) des fonctions de perte en relation avec les poids. Maintenant, nous pouvons ajuster correctement les poids.
Ajoutez la fonction de backpropagation à notre code sur Python-E:
Vérification du travail de la neurosétique
Maintenant que nous avons notre code complet sur Python-E pour effectuer une distribution directe et inverse, examinons notre réseau de neurones sur l'exemple et voyons comment cela fonctionne.
 L'ensemble parfait d'échelles
L'ensemble parfait d'échelles Notre réseau de neurones doit explorer l'ensemble parfait d'échelles pour présenter cette fonction.
Entraînons le réseau de neurones pendant 1500 itérations et voyons ce qui se passe. Considérant le calendrier des pertes sur les itérations ci-dessous, nous pouvons clairement voir que la perte diminue monotone au minimum. Cela correspond à l'algorithme de la descente de gradient, que nous avons dit plus tôt.
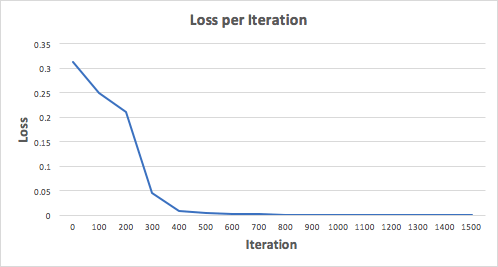
Regardons la prédiction finale (sortie) du réseau neuronal après 1500 itérations.

Nous l'avons fait!Notre algorithme de diffusion directe et de retour a montré le bon fonctionnement du réseau neuronal et les prédictions convergent sur de vraies valeurs.
Notez qu'il existe une légère différence entre les prévisions et les valeurs réelles. Ceci est souhaitable car il empêche mieux le réseau neuronal de généraliser des données invisibles.
Réflexions finales
J'ai beaucoup appris dans le processus d'écriture de zéro mon propre réseau de neurones. Bien que les bibliothèques d'apprentissage profond, telles que Tensorflow et Keras, permettent la création de réseaux profonds sans une compréhension complète du travail interne du réseau neuronal, je constate que les données de novice scientifique-am sont utiles pour obtenir leur compréhension plus profonde.
J'ai investi beaucoup de ma durée personnelle dans ce travail et j'espère que cela vous sera utile!
Nous vivons maintenant un vrai boom de réseaux de neurones. Ils sont utilisés pour la reconnaissance, la localisation et le traitement de l'image. Les réseaux de neurones sont déjà capables de faire beaucoup qui n'est pas disponible pour une personne. Il est nécessaire d'intégrer dans ce cas vous-même! Considérez le réseau Neutron qui reconnaîtra les chiffres sur l'image d'entrée. Tout est très simple: une seule couche et une fonction d'activation. Cela ne nous permettra pas de reconnaître absolument toutes les images de test, mais nous allons faire face à la majorité écrasante. En tant que données, nous utiliserons la reconnaissance mondiale dans le monde de la sélection de données de mnist.
Pour travailler avec elle à Python, il y a une bibliothèque de mnist Python. À installer:
PIP Installez Python-Mnist
Maintenant, nous pouvons télécharger des données
De mnist importation mnist mndata \u003d mnist ("/ path_to_mnist_data_folder /") tr_images, tr_labels \u003d mndata.load_training () test_images, test_labels \u003d mndata.load_testing ()
Les archives avec les données doivent être téléchargées de manière indépendante et le programme spécifie le chemin du catalogue avec eux. Maintenant, les variables TR_Images et Test_images contiennent des images pour la mise en réseau et les tests appropriés. Et les variables tr_labels et tests_labels sont des étiquettes avec la bonne classification (c'est-à-dire des chiffres d'images). Toutes les images sont la taille 28x28. Spécifiez la variable avec la taille.
Img_shape \u003d (28, 28)
Nous convertissons toutes les données dans les matrices numpues et nous les normalisons (nous donnons la taille de -1 à 1). Cela augmentera la précision des calculs.
Importer numpy en tant que np pour i in gamme (0, len (test_images)): Test_images [i] \u003d np.array (Test_images [i]) / 255 pour i in gamme (0, len (TR_Images)): TR_IMAGES [I] \u003d Np.array (tr_images [i]) / 255
Je note que, bien que les images soient prises pour représenter sous la forme d'une matrice bidimensionnelle, nous utiliserons un dimensionnement, il est plus simple pour l'informatique. Maintenant, vous devez comprendre "Qu'est-ce que le réseau de neurones"! Et ceci est juste une équation avec un grand nombre de coefficients. Nous avons un tableau de 28 * 28 \u003d 784 éléments à l'entrée et un autre poids 784 pour déterminer chaque chiffre. Pendant le fonctionnement du réseau neuronal, multipliez les valeurs des entrées de poids. Plié les données et ajoutez le décalage. Le résultat est appliqué à la fonction d'activation. Dans notre cas, ce sera relu. Cette fonctionnalité est nulle pour tous les arguments et arguments négatifs pour tous positifs.

Il y a encore de nombreuses fonctionnalités d'activation! Mais c'est le réseau neuronal le plus facile! Nous définissons cette fonctionnalité avec NUMPY
DEF RELU (x): renvoyer np.maximimum (x, 0)
Maintenant, pour calculer l'image dans l'image, vous devez calculer le résultat pour 10 séries de coefficients.
DEFN_CALCULER (IMG): REEP \u003d Liste (plage (0, 10)) pour i in gamme (0,10): r \u003d w [:, i] * img r \u003d relu (np.sum (r) + b [i] ) Respec [i] \u003d r retour np.argmax (resp)
Pour chaque ensemble, nous aurons un résultat de sortie. La sortie avec le plus grand résultat est probablement notre numéro.

Dans ce cas, 7. C'est tout! Mais non ... parce que vous devez prendre ces coefficients très quelque part. Vous devez former notre réseau de neurones. Pour ce faire, utilisez la méthode d'erreur inverse. Son essence est de calculer les sorties de réseau, de les comparer correctement, puis de supprimer les rapports dont le résultat est correct. Il faut se rappeler que pour calculer ces valeurs, une dérivée de la fonction d'activation est nécessaire. Dans notre cas, il est zéro pour tous les nombres négatifs et 1 pour tous positif. Nous définissons les coefficients au hasard.
W \u003d (2 * np.random.rand (10, 784) - 1) / 10 b \u003d (2 * np.random.rand (10) - 1) / 10 pour N dans la plage (LEN (TR_IMAGES)): IMG \u003d TR_Images [n] cls \u003d tr_labels [n] #forward propagation resp \u003d npl.zeros (10, dtype \u003d np.float32) pour i in gamme (0,10): r \u003d w [i] * img r \u003d relu (np. Somme (R) + B [i]) resp_cls \u003d np.argmax (respect) resp \u003d npl.zeros (10, dtype \u003d np.float32) resp \u003d 1.0 #back propagation true_reesp \u003d np. Zéros ( 10, dtype \u003d np.float32) True_Resp \u003d 1.0 Erreur \u003d REEE - TRUE_RESP Delta \u003d Erreur * ((REEE\u003e \u003d 0) * NP.ONES (10)) Pour I In Gamme (0.10): W [I] - \u003d NP .Dot (img, delta [i]) b [i] - \u003d delta [i]
Dans le processus d'apprentissage, les coefficients seront légèrement similaires à ceux-ci:
Vérifiez la précision du travail:
Defn_calculate (IMG): respect \u003d liste (plage (0, 10)) pour i in gamme (0,10): r \u003d w [i] * img r \u003d np.maximum (np.sum (r) + b [i] , 0) #Relu resp [i] \u003d r retour np.argmax (respect) Total \u003d len (test_images) Valider \u003d 0 invalide \u003d pour i in gamme (0, total): img \u003d test_images [i] prédit \u003d nn_calculate (IMG ) True \u003d Test_Labels [i] Si prédit \u003d\u003d true: valide \u003d valide + 1 autre: invalide.append (((("image": img, "prédit": prédit, "vrai": vrai)) Imprimer ("Précision () ". Format (valide / total))
J'ai eu 88%. Pas si cool, mais très intéressant!